ADS test adequacy progress update from current implementation and InterFuser RQ1 artifacts
June 5, 2026
오늘 발표는 논문 목차가 아니라 ICSE 2027 논문 flow 자체를 따라갑니다. 핵심 메시지는 BVC가 "테스트를 얼마나 했는가"가 아니라 "실행된 ADS 행동 공간을 얼마나 커버했는가"를 설명하는 post-test adequacy metric이라는 점입니다.
Motivation
ML-Enabled Testing Is Hard
ADS behavior emerges from model + code + traffic
Failures are rare, contextual, and expensive to reproduce
DNN coverage alone misses system-level behavior
A scenario can pass while still exercising little behavior
ADS testing observes an integrated cyber-physical loop, not just model outputs.
Adequacy should talk about exercised behavior, not only inputs.
첫 슬라이드는 문제를 크게 잡습니다. ML-enabled system은 전통 소프트웨어처럼 로직이 명시적이지 않고, ADS는 모델의 예측, planner/controller code, 주변 traffic이 함께 닫힌 루프를 만듭니다. DeepXplore는 neuron coverage를, DeepGauge는 더 다양한 DNN testing criteria를 제안했지만, 이들은 주로 모델 또는 입력 수준의 adequacy에 가깝습니다. InterFuser 같은 ADS는 멀티모달 센서 fusion과 rare traffic 상황에서의 안전성이 핵심이라 system-level behavior를 봐야 한다는 흐름으로 다음 슬라이드에 연결합니다.
Diversity is often defined over scenario parameters
The goal is to expose more critical behaviors
Scenario-based testing explores a structured but huge input space.
여기서는 simulation-based testing을 소개합니다. CARLA는 도심 주행 시뮬레이터로 센서, 환경 조건, 도시 asset을 제공하고, DeepTest 이후 ADS testing 연구는 scenario input을 자동 생성하거나 mutate하는 방향으로 발전했습니다. SAMOTA는 surrogate-assisted many-objective search, scenoRITA는 fully mutable scenario representation, DoppelTest는 multi-ADS doppelganger 구조, BehAVExplor는 ego behavior diversity를 feedback으로 사용합니다. 즉 기존 연구는 "어떤 scenario를 만들 것인가"를 잘 다룹니다.
Motivation
Input Diversity Still Leaves A Gap
Critical-scenario search finds bugs efficiently
But it rarely answers: when is a suite adequate?
Scenario coverage can ignore ADS-internal behavior
More scenarios can still be behaviorally redundant
The missing object is a post-test coverage estimate over observed behavior.
We need a stopping/assessment signal after execution.
RAND의 Driving to Safety는 AV 안전성을 road testing만으로 통계적으로 입증하려면 엄청난 mileage가 필요하다는 한계를 보여줍니다. Simulation은 그 비용을 낮추지만, scenario를 몇 개 실행해야 충분한지에 대한 adequacy 기준은 여전히 부족합니다. 특히 같은 suite size라도 ADS가 실제로 경험한 behavior diversity는 다를 수 있습니다. 그래서 input coverage에서 behavior coverage로 관점을 옮깁니다.
Motivation
Behavior Vector Space
Collect signals during each execution window
Map each window to a normalized behavior vector
Define coverage over the observed vector universe
Keep the claim empirical, not global reconstruction
Behavior Vector Space embeds execution-induced behavior, not raw scenario syntax.
Behavior Vector Space는 ICSE DS 2026에서 잡은 핵심 아이디어를 ICSE 2027 논문용으로 post-test adequacy metric으로 정리한 것입니다. 각 execution window에서 ego state, code/control, ML output/hidden state, sensitivity signal을 모아 벡터화합니다. 중요한 caveat는 "진짜 global behavior space를 복원한다"가 아니라, 실행된 scenario pool이 유도한 observed behavior-vector universe 위에서 coverage를 추정한다는 점입니다.
Motivation
Motivation And Goal
Input: executed scenario suite and ADS implementation
Output: behavior-vector coverage and validity evidence
Question: did the suite exercise diverse ADS behavior?
Evidence: higher BVC should explain unique failures
The paper turns behavior diversity into a measurable adequacy claim.
Core thesis: BVC estimates how much observed ADS behavior a suite covers.
여기서 thesis를 명확하게 둡니다. BVC는 generation algorithm이 아니라 post-test adequacy metric입니다. 입력은 이미 실행된 scenario suite와 ADS이고, 출력은 coverage score와 그 score가 unique failure discovery를 설명하는지에 대한 evidence입니다. 이 슬라이드 이후부터는 접근법으로 넘어갑니다.
Approach
Overall Approach
Execute scenarios on a fixed ADS
Record simulator, code, ML, sensitivity signals
Aggregate windows into behavior vectors
Score suite coverage over observed behavior
Validate against unique failure discovery
BVC sits after execution and before adequacy interpretation.
전체 approach는 실행 후 분석입니다. Scenario를 실행하고, signal collector가 창 단위로 데이터를 모읍니다. 이후 build_vectors가 normalization, PCA, weighting을 적용해 behavior_trace를 만들고, RQ1은 이 벡터로 macro/micro coverage와 failure association을 계산합니다.
Approach
Signal Fusion
Ego/simulator: state, control, traffic context
Code/control: planner and controller decisions
ML state: outputs, hidden representations
Sensitivity: JVP and Hessian-quadratic probes
Leakage control removes shortcut failure proxies
The vector is a disciplined fusion of allowed signal families.
Contribution은 "많은 signal을 넣었다"가 아니라 leakage-controlled construction protocol입니다. Failure label, timeout flag 같은 shortcut proxy는 제외하고, ADS taxonomy에 맞는 signal만 사용합니다. InterFuser는 ego.state, control/controller, outputs, hidden_state, jvp, hessian_quad를 사용합니다. Pylot은 stream signal과 ML probe 상태가 핵심이며 현재 instrumentation completeness를 계속 확인해야 합니다.
Approach
Scene Behavior Vector
z_A(w) = T(φ_A(w)) ∈ R^d
Windowed aggregation over execution traces
Z-score normalization over the corpus
Zero-variance removal and clipping
Optional block-wise PCA for high-dimensional blocks
A scene behavior vector summarizes one ADS behavior window.
수식은 plan.md의 formal definition을 그대로 요약합니다. 하나의 behavior window w에서 φ_A(w)를 모으고, T가 filtering, aggregation, normalization, zero-variance drop, clipping, optional PCA를 수행합니다. 이 결과가 z_A(w)이고, coverage는 이 벡터 공간에서 계산됩니다.
Approach
Scenario-Level BVs
V_A(S) = ⋃_{s∈S} V_A(s)
U_A = ⋃_{s∈D} V_A(s)
Each scenario induces many behavior windows
A suite is the union of its scenario vectors
Coverage is measured against the executed pool
Scenario-level sets connect execution artifacts to suite adequacy.
Scenario 하나는 하나의 point가 아니라 여러 ego trace와 window의 set입니다. Suite는 scenario set의 union이고, observed universe는 실행된 전체 scenario pool D의 union입니다. 이 정의 덕분에 suite-level adequacy를 finite set coverage problem으로 볼 수 있습니다.
Approach
Macro And Micro Coverage
Macro: anchor-complete cells in full vector space
Micro: block-level occupancy proxy
Radius from nearest-other-scenario quantiles
Main conservative metric: macro q25
Robustness reports q05, q10, q25, q50
Macro is geometric cell coverage; micro is block-level occupancy.
Macro coverage는 full-dimensional normalized L2 거리에서 anchor cell을 만들고, radius/2 이내에 들어온 vector만 assign합니다. 그래서 pairwise diameter를 radius로 제한하는 보수적 metric입니다. Micro는 signal block 단위 hash bin occupancy라 정확한 geometric union volume은 아니지만 scalable한 proxy입니다. RQ1에서는 둘 다 보고, main은 macro_cell_coverage_q25로 둡니다.
Evaluation
Research Questions
RQ1. [Validity]
Is BVC positively associated with unique failure discovery?
RQ2. [Incremental Value]
Does BVC explain failures beyond scenario/input and simpler execution baselines?
RQ3. [Construct Validity]
Which signal families make BVC useful, and do they align with failure semantics?
RQ4. [Robustness]
How sensitive and practical is BVC after signal collection?
Evaluation은 네 개 RQ로 구성합니다. RQ1은 이미 InterFuser 결과가 있고 Pylot은 진행 중입니다. RQ2는 baseline 대비 incremental value, RQ3는 signal family가 failure semantics와 맞는지, RQ4는 construction choice와 비용에 대한 robustness입니다.
Evaluation
Experimental Setup
Component
Current plan
ADS
InterFuser complete; Pylot running
Simulator
CARLA / Drivora scenario runner
Suite sizes
5, 10, 25, 35, 50, 75, 100
Suite specs
100 random suites per size
Windows
0.25s, 0.5s, 1.0s
Schemas
code_only, ml_only, all
RQ1 reuses fixed suites across schemas and windows.
Setup은 reproducibility 관점에서 설명합니다. InterFuser는 현재 200개 성공 scenario corpus로 RQ1이 완료되었습니다. Pylot은 RQ1 실행 중이며 내일 완료가 목표입니다. Suite는 크기별 100개, 총 700개 fixed suite specs를 모든 schema/window 조합에서 재사용합니다.
Evaluation
Unique Failure Definition
Failure event: one oracle/infraction occurrence
Type-unique: failure family only
Coarse unique: type plus coarse location
Contextual unique: type plus scenario context
Primary target: contextual unique failures
Contextual uniqueness avoids treating repeated symptoms as new evidence.
Unique failure는 RQ1 validity의 target입니다. 단순 failure event count는 같은 현상의 반복을 많이 세기 때문에 primary target으로 부적절합니다. Type-level은 너무 coarse합니다. 그래서 primary는 contextual_unique_failure_count로 두고, coarse/type/event count는 construct-validity check로 보고합니다.
Evaluation
RQ1 InterFuser Experiment
Mode: adequacy_fullset
700 fixed suite specs reused everywhere
3 schemas × 3 windows × 7 suite sizes
Macro/micro metrics at q05, q10, q25, q50
Correlation and OLS HC3 regression
Primary choice
Value
Adequacy
macro_cell_coverage_q25
Failure target
contextual_unique_failure_count
Distance
L2 / sqrt(dim)
Controls
suite_vector_count
Rows
63 primary combinations
RQ1의 현재 구현은 adequacy_fullset입니다. 먼저 suite_specs.json을 만들고, 모든 schema/window에서 같은 suite를 사용합니다. Spearman은 suite size 안에서 계산하고, regression은 contextual unique failure를 BVC와 suite_vector_count로 설명하며 HC3 robust standard error를 사용합니다.
Evaluation
RQ1 Dataset Snapshot
200
Successful scenarios
588
Ego traces
514
Failure events
249
Contextual unique
700
Fixed suites
1.38M
Vector rows
3,637
All normalized dim
63
Primary rows
이 슬라이드는 결과 해석 전에 dataset scale을 빠르게 보여줍니다. 200개 successful scenario, 588 ego traces, 514 failure events, contextual unique failure 249개입니다. Window와 schema 전체로 보면 약 1.38M behavior vector row가 분석에 들어갑니다.
Evaluation
Adequacy Rises With Suite Size
Coverage increases monotonically with suite size
Macro grows conservatively from near zero
Micro starts higher and saturates faster
code_only is strong in macro q50
all is strongest in micro q50
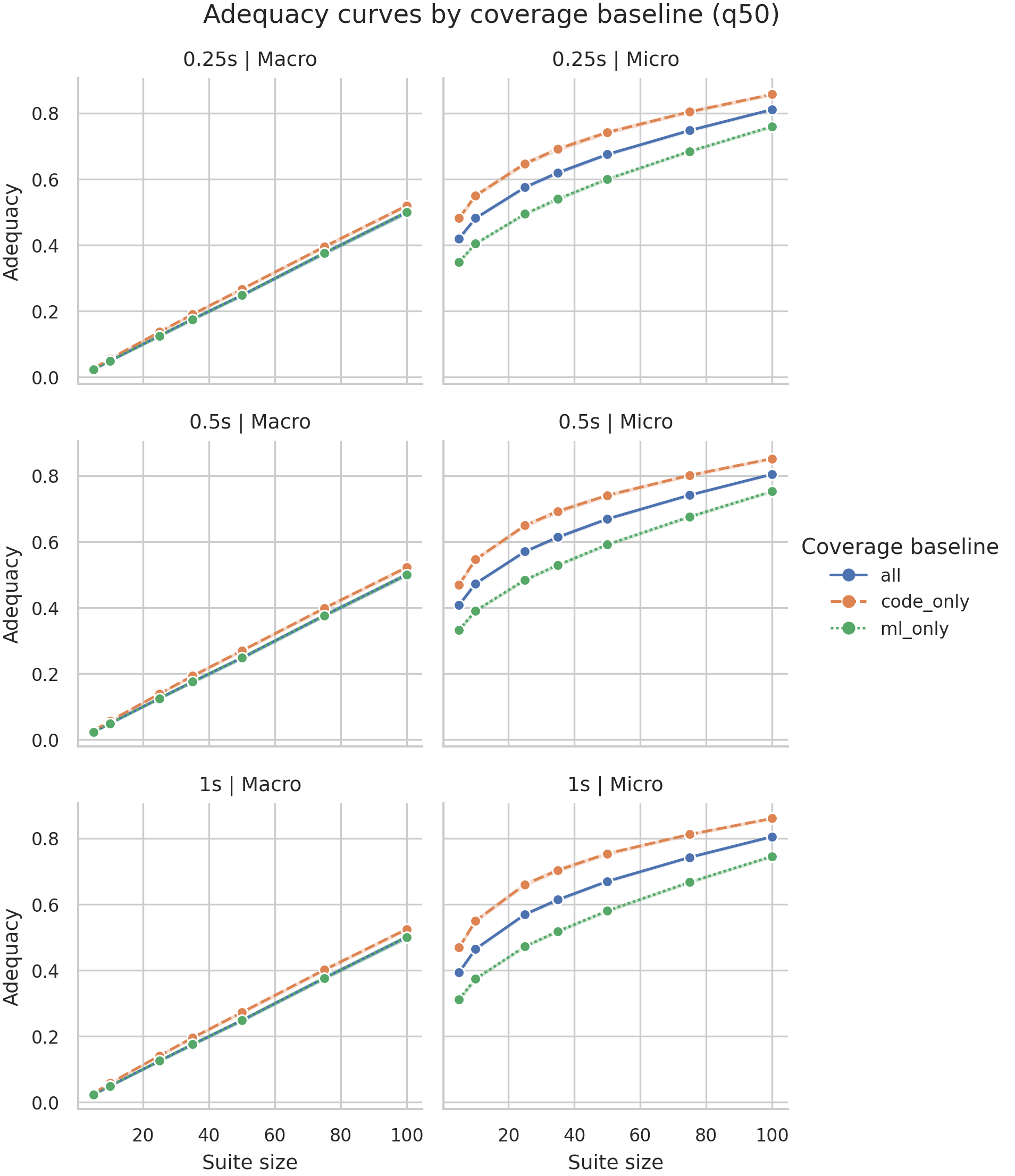
Adequacy curves by coverage baseline (q50).
이 figure는 suite size가 커질수록 coverage가 올라가는 기본 sanity check입니다. Macro는 full-vector cell이므로 보수적으로 증가하고, micro는 block occupancy라 더 높게 시작합니다. 현재 InterFuser에서는 macro에서는 code_only가 강하고, micro에서는 fused all이 가장 강한 패턴이 보입니다.
Evaluation
Coverage Tracks Unique Failures
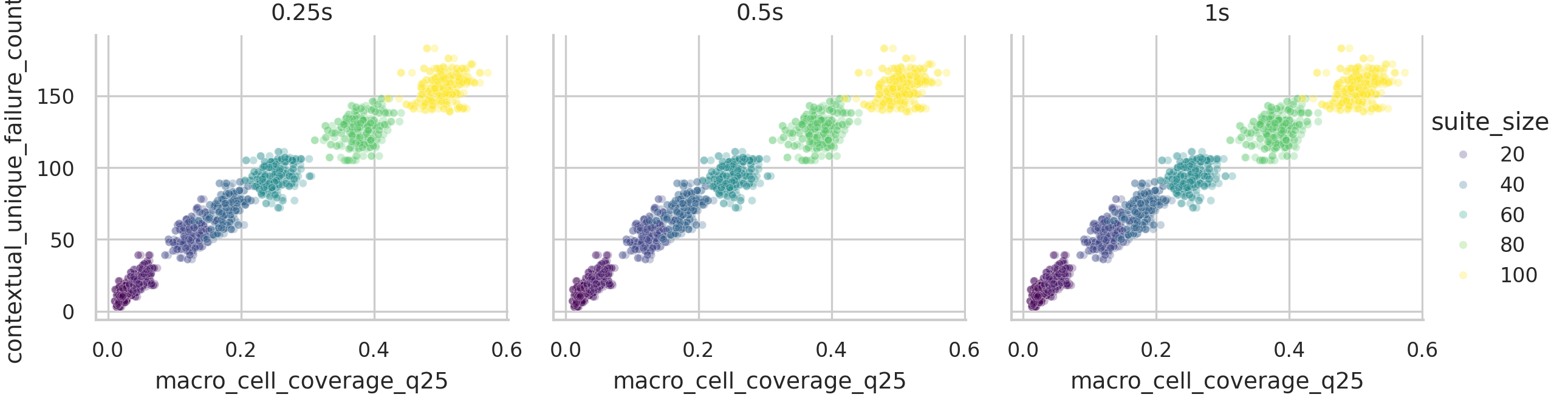
Primary macro q25 coverage vs contextual unique failures.
Higher macro q25 coverage aligns with more contextual unique failures
The pattern repeats across 0.25s, 0.5s, and 1.0s windows
Suite size explains level, BVC explains ordering within size
This is the main validity picture
이 scatter는 primary result를 직관적으로 보여줍니다. 점들이 suite size별로 band를 만들지만, 같은 band 안에서도 BVC가 높은 suite가 더 많은 contextual unique failure를 찾는 경향이 있습니다. 발표에서는 "size가 아니라 size 안의 ordering"을 강조하면 좋습니다.
Evaluation
Association Holds Across Sizes
Primary Spearman: 63/63 positive
Mean Spearman: 0.389
Range: 0.232 to 0.555
Positive in every schema-window-suite cell
Strong support for InterFuser validity
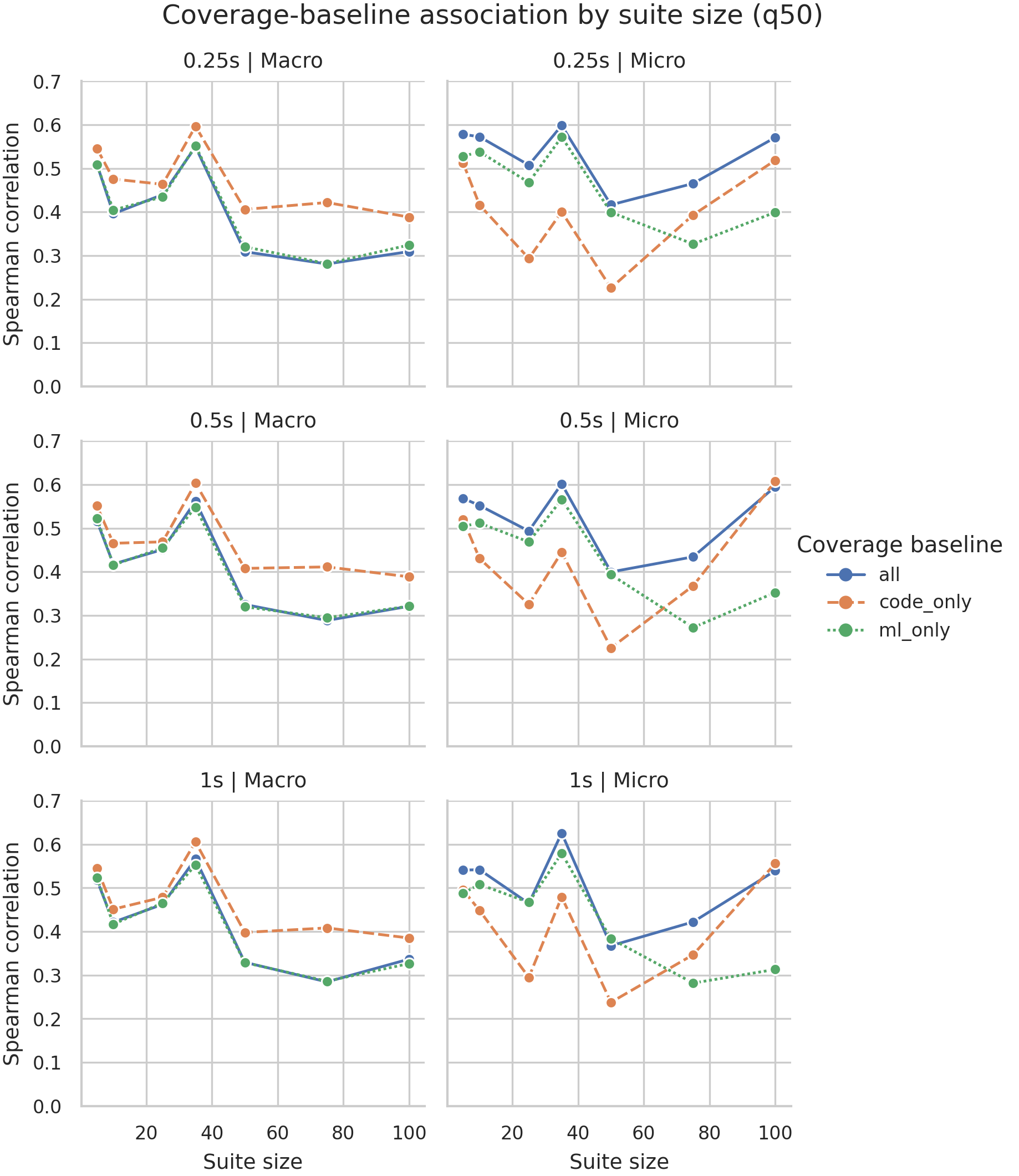
Spearman association by suite size (q50 view shown).
Primary metric macro_cell_coverage_q25와 contextual_unique_failure_count 사이의 Spearman은 63개 schema-window-suite size 조합 모두에서 양수입니다. 평균 0.389, 범위는 0.232에서 0.555입니다. 이 결과는 InterFuser에 대해서는 strong support로 쓰되, cross-agent claim은 Pylot 결과 이후로 남깁니다.
Evaluation
Controlled Models Support BVC
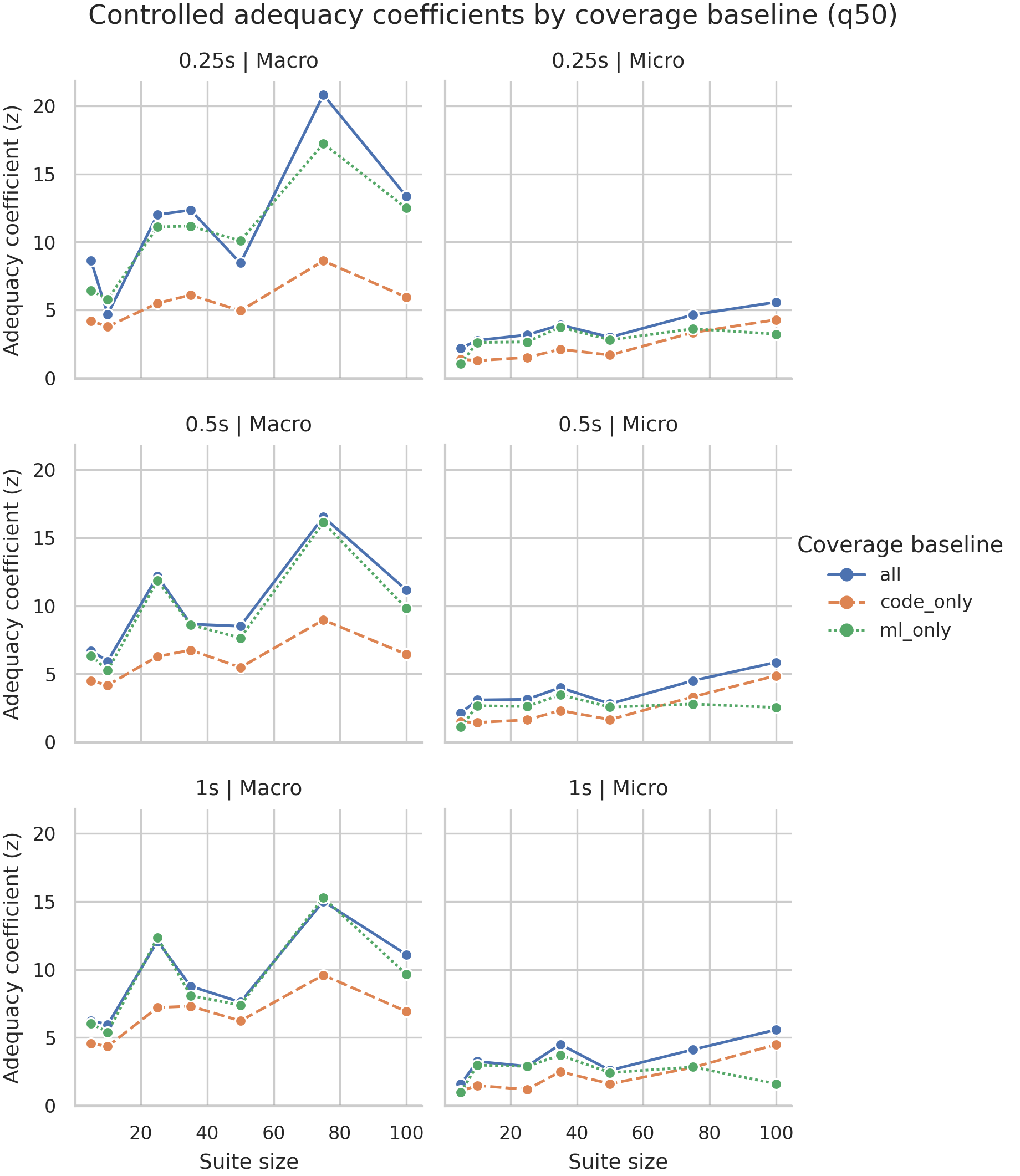
Adequacy coefficient z-scores after controlling for suite vector count.
Primary BVC coefficients: 63/63 positive
Significant positive: 54/63 at p < 0.05
Significant negative: 0/63
BVC remains explanatory after execution volume control
Interpretation: not just more logged vectors
Regression은 단순히 많이 실행했기 때문에 failure를 많이 찾았다는 설명을 줄이기 위해 suite_vector_count를 control합니다. Primary row에서 BVC coefficient는 63개 모두 양수이고 54개가 p<0.05로 유의합니다. suite_vector_count는 평균적으로 음수 방향이므로, 현재 결과는 "execution volume"보다 "behavior space coverage" 설명력이 더 직접적이라는 해석을 지지합니다.
Evaluation
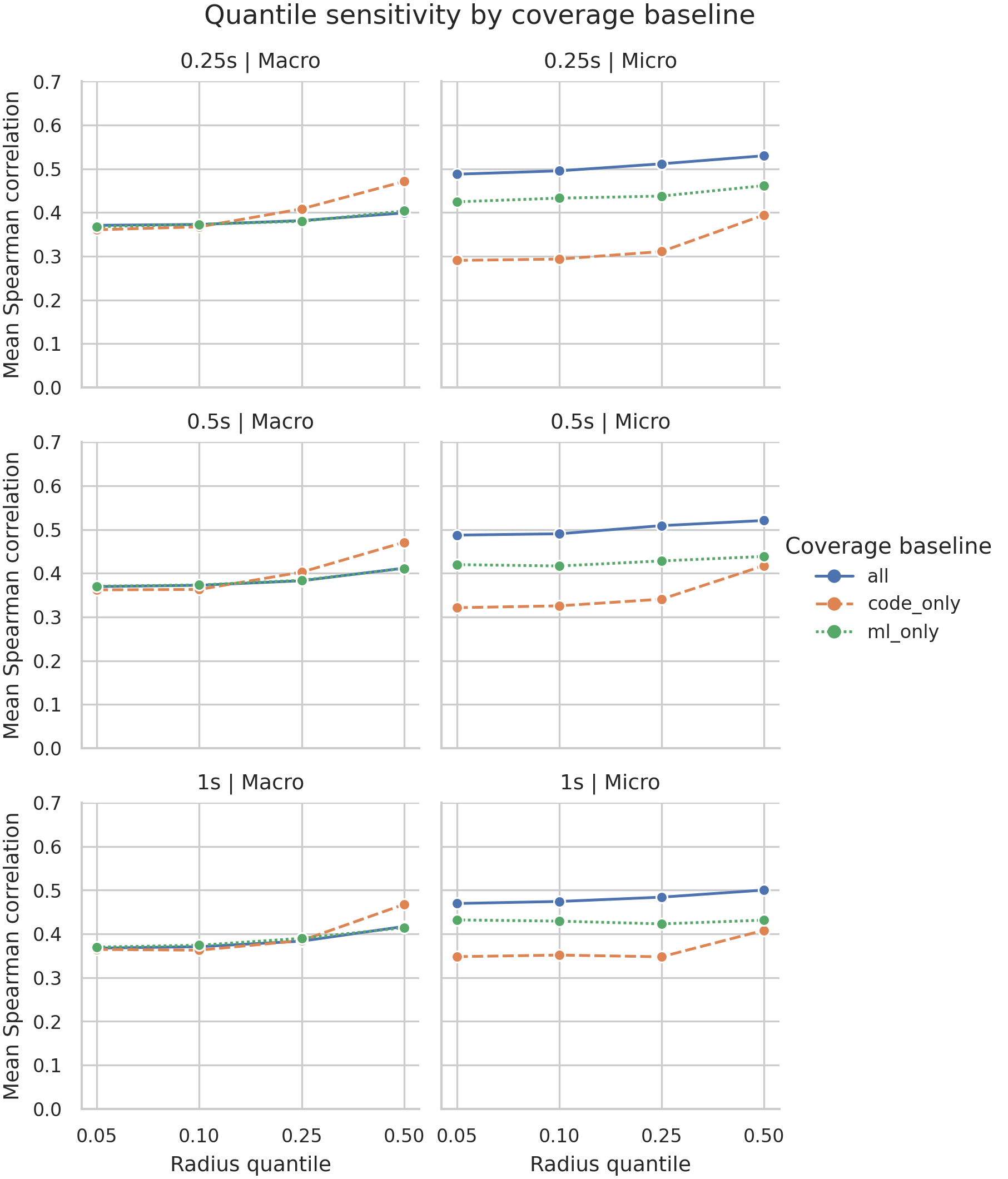
Quantiles And Families Matter
Macro q25 is the conservative primary metric
q50 often gives stronger empirical association
Micro/all is strong but less geometrically exact
code_only, ml_only, all are separate baselines
Do not collapse everything into one BVC score
Quantile sensitivity by coverage family and baseline.
이 슬라이드는 RQ1을 너무 단일 숫자로 축약하지 않기 위한 장치입니다. Macro q25는 보수적인 main metric으로 유지하지만, q50과 micro/all 조합은 empirical association이 더 강하게 나올 수 있습니다. 논문에서는 code_only, ml_only, all을 단순 sensitivity가 아니라 서로 다른 coverage baseline으로 보고해야 합니다.
Evaluation
RQ2 Baseline Comparison Plan
Reuse RQ1 fixed suite specs
Compare against random suite sampling
Scenario/input-space coverage baselines
Execution-volume and trace-count baselines
Single-signal or family-only adequacy baselines
RQ2 asks whether BVC adds value beyond simpler baselines.
RQ2는 incremental value입니다. 기존 scenario-space coverage, parameter diversity, random, execution volume, 그리고 single-signal adequacy와 비교합니다. 핵심 분석은 correlation 비교와 paired comparison, 그리고 regression에서 BVC가 baseline control 이후에도 설명력을 추가하는지입니다.
Evaluation
RQ3 Signal Semantics Plan
Ablate signal families and schema variants
Measure association with contextual failures
Map signal families to failure families
Use GA/search diagnostics as interim evidence
Expected output: family × failure heatmap
RQ3 turns predictive signal families into construct-validity evidence.
RQ3는 어떤 signal family가 실제로 BVC를 유용하게 만드는지 묻습니다. 단순히 performance가 좋은 schema를 고르는 것이 아니라, red-light, offroad, wrong-lane, collision, timeout, stuck 같은 failure semantics와 signal family가 어떻게 맞물리는지를 보여야 합니다.
Cost: signal collection, vector build, cached scoring
RQ4 checks whether the claim survives reasonable construction choices.
RQ4는 reviewer가 물을 법한 sensitivity를 한 번에 정리합니다. 현재 구현은 L2/sqrt(dim)을 사용하고, cosine과 group-weighted distance는 planned extension입니다. 비용 측정은 signal collection 자체와 offline scoring을 분리해야 합니다. BVC의 장점은 cache 이후 repeated suite analysis가 싸다는 점입니다.
Next
TODO Through June 30
Jun 5-6
Finish Pylot RQ1 run and sanity-check artifacts
Jun 7-9
Summarize Pylot RQ1 and align cross-agent tables
Jun 10-18
Implement and run RQ2 baselines
Jun 15-23
Run RQ3 signal-family semantics
Jun 20-27
Run RQ4 robustness and cost analysis
Jun 12-30
Write paper sections in parallel
Pylot RQ1: in progress, target June 6
RQ2/RQ3/RQ4 share RQ1 suite specs
Summaries and figures must stay agent-scoped
By June 30: full experiment narrative draft
Priority: finish cross-agent RQ1 first, then reuse caches aggressively.
일정은 2026년 6월 5일 기준입니다. Pylot RQ1은 진행 중이며 내일인 6월 6일까지 완료를 목표로 둡니다. 이후 RQ2, RQ3, RQ4는 RQ1 suite specs와 vector/cache를 최대한 재사용해야 합니다. 논문 작성은 실험이 끝난 뒤 몰아서 하는 것이 아니라 RQ2/3/4와 병행합니다.
Current Progress
Behavior Vector Coverage for ADS Test Adequacy
InterFuser RQ1 supports the core validity claim
{'Next checkpoint': 'Pylot RQ1 and baseline comparison'}
June 2026
마지막은 짧게 정리합니다. 현재 InterFuser RQ1은 thesis를 강하게 지지합니다. 다만 cross-agent 일반화는 아직 말하지 않고, Pylot RQ1과 RQ2 baseline comparison이 다음 가장 중요한 checkpoint입니다.